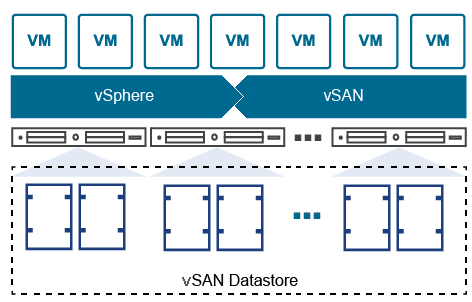
Comment les données sont structurées dans un datastore vSAN et comment le vSAN utilise plusieurs hôtes dans un cluster pour assurer la redondance des données ? Sans oublier que tout cela est configuré au niveau de la couche logicielle et non matérielle.
Storage Policy-Based Management (SPBM)
Dans les baies de stockage traditionnelles, vous créez généralement des volumes ou des LUN et vous les présentez à vSphere où ils sont formatés sur le système fichuer VMFS pour être utlisés sur une machine virtuelle. C’est à ce niveau de volume que de nombreux paramètres sont configurés, comme la protection RAID et la capacité, ainsi que des services tels que l’approvisionnement thin, la réplication, la compression et le cryptage. Cette approche peut augmenter les frais administratifs lors du déploiement d’une nouvelle charge de travail, car vous devrez savoir en avance quel volume placer sur la machine virtuelle. Dans certaines grandes organisations, la configuration du stockage peut être prise en charge par un ensemble différent d’administrateurs, ce qui peut ajouter une couche de complexité supplémentaire. Avec vSAN, vous êtes libre d’utiliser ces fonctionnalités ou services pour chaque machine virtuelle plutôt que de vivre dans les limites d’un modèle de gestion LUN.

Les politiques de stockage sont créées dans vCenter et sont attribuées aux machines virtuelles et aux objets tels que le disque virtuel (fichier vmdk). Si les exigences d’une charge de travail ou d’une machine virtuelle changent, la politique peut être simplement modifiée à la volée. Vous n’aurez pas besoin d’éteindre la machine au préalable ni d’effectuer une quelconque forme de migration de stockage.
Disponibilité des données
Dans la première partie de cette série, j’ai mentionné que le vSAN n’utilise aucune forme de RAID matériel pour protéger les données et que la protection des données est plutôt configurée au niveau de la couche logicielle. Le niveau primaire de tolérance aux pannes (pFTT – Primary level of Failures To Tolerate) défini dans une politique de stockage détermine le nombre de pannes que le cluster vSAN peut tolérer tout en maintenant la disponibilité des données. Le paramètre pFTT configuré le plus souvent est 1, ce qui signifie que le cluster pourra tolérer la perte d’un seul périphérique de cache ou de capacité, d’une carte réseau ou d’un hôte tout en maintenant la disponibilité des données.

Cet exemple montre comment les données sont distribuées entre les hôtes en utilisant une politique pFTT de 1. Nous avons deux copies du fichier vmdk, chacune sur un hôte séparé, plus un fichier témoin sur un troisième hôte pour servir de witness en cas de défaillance du réseau. Comme les données sont effectivement reflétées, la quantité de capacité consommée sur le magasin de données vSAN est deux fois supérieure à la taille originale du vmdk. Par exemple, si la machine virtuelle dispose d’un disque de 100 Go, elle consommera 200 Go de capacité sur le magasin de données. Il est possible de configurer différents niveaux de protection si certaines charges de travail sont plus critiques que d’autres. Comme tout cela est dicté par la politique, c’est très facile à réaliser. Il est important de noter qu’un niveau de protection plus élevé consommera plus de capacité et nécessitera un plus grand nombre d’hôtes. Le tableau ci-dessous donne un exemple de la capacité consommée et du nombre d’hôtes requis pour chaque niveau de pFTT.

Comme vous pouvez le constater, l’augmentation du niveau de pFTT au-dessus de 1 a un effet assez spectaculaire sur l’efficacité du stockage au sein du vSAN. Avec la sortie de la version 6.2, de nouvelles fonctionnalités ont été ajoutées pour y remédier.
Erasure Coding
Cette fonctionnalité n’est disponible qu’avec les déploiements all-flash et nécessite un minimum de 4 hôtes. Il est important de noter que la taille du cluster n’a pas besoin d’être un multiple de 4.
Le erasure coding est similaire à la façon dont les RAID 5 et 6 fonctionnent dans une baie de stockage traditionnelle, mais souvenez-vous que nous ne configurons aucune forme de RAID matériel et que tout cela est configuré à l’aide de politiques de stockage. Le erasure coding offre le même niveau de redondance qu’un miroir, mais avec une surcharge de stockage moindre, ce qui le rend plus efficace. Comme pour le RAID matériel, les données sont divisées en plusieurs morceaux et réparties sur plusieurs hôtes avec des données de parité également écrites pour protéger contre la corruption ou la perte de données.
Le erasure coding RAID5 nécessite un minimum de 4 hôtes et fournit un pFTT de 1. Les données sont réparties sur 3 hôtes, un quatrième hôte détenant les données de parité.

Le erasure coding RAID6 nécessite un minimum de 6 hôtes et fournit un pFTT de 2. Les données sont réparties sur 4 hôtes avec des données de parité écrites sur deux autres hôtes.

Le tableau ci-dessous montre comment le erasure coding se compare à la mise en miroir à l’aide de notre machine virtuelle de 100 Go.

Une considération importante dans le choix de la méthode de protection requise est le surcoût généré par le erasure coding. C’est ce que l’on appelle communément l’amplification des entrées/sorties. En fonctionnement normal, il n’y a pas d’amplification des E/S de lecture, mais il y a une amplification des E/S d’écriture, car les données de parité doivent être mises à jour à chaque nouvelle écriture de données. Le processus peut être décrit comme suit
- Lire la partie du fragment qui doit être modifiée
- Lire les parties pertinentes des anciennes données de parité pour recalculer leurs valeurs
- Combiner les anciennes valeurs avec les nouvelles données pour calculer la nouvelle parité
- Ecrire les nouvelles données
- Ecrire la nouvelle parité
Pour le RAID5, cela se traduit par 2 lectures et 2 écritures sur le stockage. Pour le RAID6, cela se traduit par 3 lectures et 3 écritures sur la mémoire. Cela signifie qu’il y a une augmentation du trafic réseau entre les nœuds pendant les opérations d’écriture par rapport à la mise en miroir. De plus, si un nœud devait échouer, une amplification des entrées/sorties peut également se produire pendant les opérations de lecture. Ne vous laissez pas décourager. Comme les dispositifs flash peuvent fournir un nombre important d’IOPS, l’amplification des E/S peut être moins préoccupante si on la compare aux économies de capacité réalisées par rapport à la mise en miroir. Il n’existe pas d’approche unique et avec le vSAN, vous êtes libre de choisir les charges de travail qui nécessitent des performances élevées (mise en miroir) et celles qui nécessitent une efficacité de la capacité (erasure coding). N’oubliez pas que tout cela est dicté par des politiques de stockage que vous contrôlez et que vous pouvez modifier à la volée.