A ce stade, on a couvert les différentes méthodes utilisées par vSAN pour protéger les données sur un cluster et même entre les sites. Dans cet article, nous allons savoir comment le vSAN gère les pannes et les processus de récupération des données au niveau machine virtuelle en respectant les exigences de politique stockage.
Défaillances
Le vSAN se base sur deux catégories de défaillances martérielles, à savoir une absence et une dégradation.
Absence d’un host – le vSAN attend 60 minutes avant de tenter de récupérer les objets et les composants.
Dégradation d’un host – le vSAN tentera immédiatement de récupérer les objets et composants lorsque cela est possible.
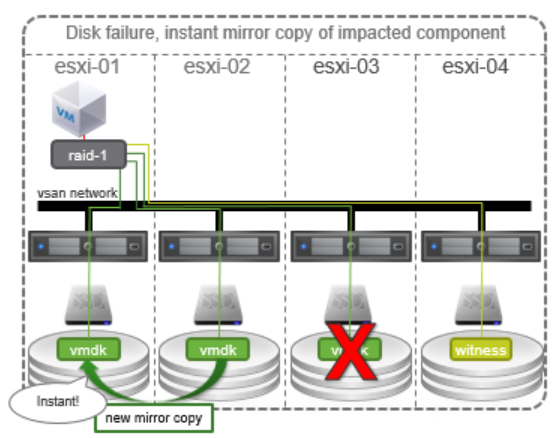
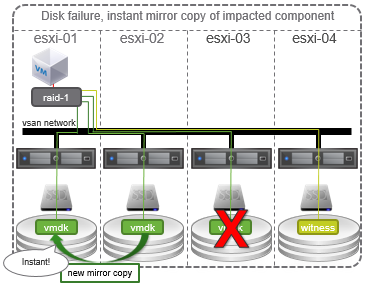
Si un disque tombe en panne dans un hôte vSAN et que des codes d’erreur sont détectés par le vSAN, tous les composants affectés sont marqués comme étant dégradés et le vSAN tentera de créer une nouvelle copie des données si des ressources sont disponibles pour le faire. S’il n’y a pas de ressources disponibles, il attendra que la panne soit résolue. Pendant cette période, les machines virtuelles affectées par cette panne seront toujours disponibles et continueront à fonctionner. Si le périphérique de cache tombe en panne, le vSAN marque l’ensemble du groupe de disques comme étant dégradé.
Si un disque tombe en panne sans avertissement (aucun code d’erreur détecté), vSAN marque tous les composants concernés situés sur l’appareil comme absents et une temporisation de 60 minutes est lancée. Il peut arriver qu’un disque soit accidentellement retiré d’un hôte et que, si le disque est replacé dans cette fenêtre de temps, les composants soient resynchronisés, le vSAN continue à fonctionner normalement. Ce scénario est préférable à l’état dégradé pour économiser les ressources consommées par une reconstruction. Si le délai de 60 minutes expire, les composants marqués comme absents seront reconstruits sur d’autres hôtes du cluster si des ressources sont disponibles pour le faire. Si le périphérique de capacité tombe en panne, le vSAN marque l’ensemble du groupe de disques comme absent.
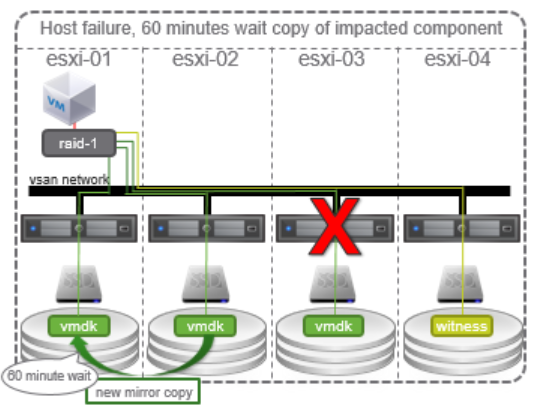
Si un hôte échoue au vSAN, tous les objets associés à l’hôte sont marqués comme absents par le vSAN et la minuterie par défaut de 60 minutes démarre. Si l’hôte revient en ligne dans ce délai, les composants sont resynchronisés et le vSAN continue à fonctionner normalement. Si le temps dépasse 60 minutes, les composants et les objets affectés sont reconstruits sur d’autres hôtes du cluster s’il y a des ressources pour le faire.
Maintenance Mode and Self Healing

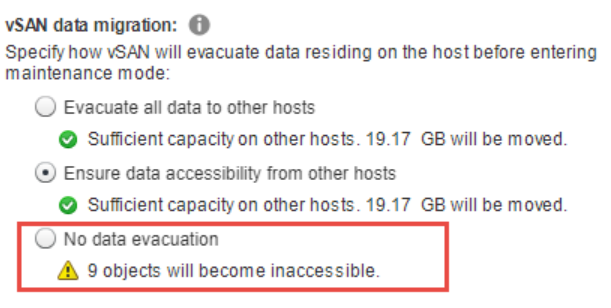
L’après mes retours d’expériences, un domaine qui a causé une certaine confusion est celui de ce qui se passe lorsqu’un hôte est placé en mode de maintenance. Il existe plusieurs options pour placer un hôte en mode de maintenance. Les raisons pour lesquelles on place un hôte en mode maintenance peuvent influencer le choix fait. S’il s’agit simplement de redémarrer l’hôte, vous pouvez alors choisir le choix par défaut qui permet de s’assurer que les données sont accessibles à partir d’autres hôtes. Dans l’exemple montré, il y a un risque associé à cette décision dans la mesure où 9 objets deviendront non conformes. Cela ne signifie pas que les machines virtuelles seront inaccessibles, mais qu’elles ne seront plus conformes à la politique qui leur a été assignée, qui consiste dans ce cas à tolérer une seule défaillance de l’hôte. Toutes les machines virtuelles dont la politique pFTT est définie à 0 et dont les composants sont situés sur cet hôte seront marquées comme inaccessibles. Cela signifierait une perte de données s’il n’y a pas suffisamment de copies des données pour maintenir la disponibilité. À titre d’exemple, on va essayer de mettre un deuxième hôte du cluster de trois hôtes en mode de maintenance. Cela m’avertit que 9 objets deviendront inaccessibles, donc ce n’est probablement pas une bonne idée d’aller de l’avant avec cela.
Si l’hôte placé en mode de maintenance est supprimé, le choix évident est de migrer toutes les données vers d’autres hôtes du cluster. Cela conduit à une autre considération de conception sur le nombre minimum d’hôtes à avoir dans un cluster.
Une nouvelle fonctionnalité de la version 6.6 est la possibilité d’effectuer une vérification préalable si vous devez retirer un disque ou un groupe de disques du cluster. Comme pour le placement d’un hôte en mode de maintenance, trois options sont disponibles.
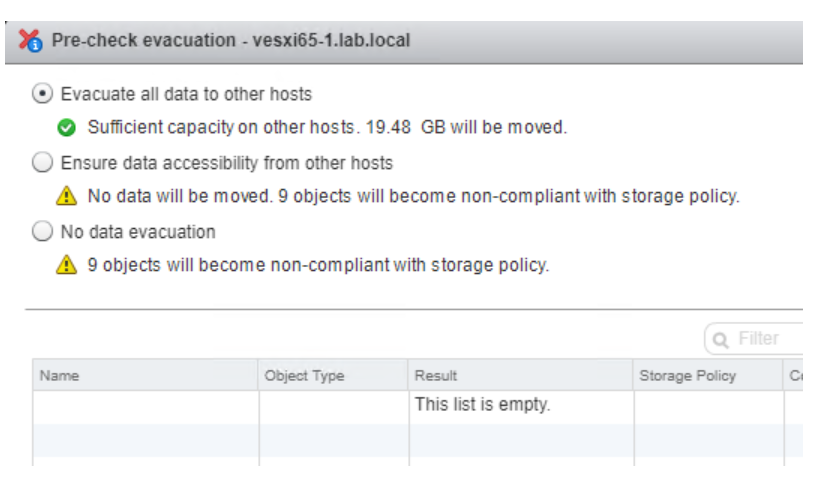
Assurer l’accessibilité
Cela garantit que toutes les machines virtuelles sur cet hôte resteront accessibles si l’hôte est arrêté ou retiré du cluster.
Migration complète des données
Toutes les données seront transférées de l’hôte choisi vers d’autres membres du groupe. Comme une grande quantité de données sera copiée, cette option consommera le plus de ressources et prendra un certain temps. Cependant, elle garantit que toutes les machines virtuelles restent conformes à la politique de stockage qui leur a été attribuée.
Pas de migration de données
vSAN ne migrera aucune donnée de l’hôte sélectionné. Cela signifie que certaines machines virtuelles peuvent devenir inaccessibles si l’hôte est arrêté ou retiré du cluster. Il est recommandé de ne pas utiliser cette option, sauf dans des circonstances spécifiques, car elle comporte un risque de perte de données.
Comme vous pouvez le voir, vSAN prendra des décisions intelligentes en fonction des informations dont il dispose pour gérer les pannes et la maintenance au sein du cluster. vSAN peut reconstruire automatiquement les données sur un autre hôte ou un autre disque pour s’assurer que les machines virtuelles sont conformes à la politique qui leur a été assignée. Cela conduit à une décision importante concernant le nombre minimum d’hôtes nécessaires dans un cluster vSAN.
Alors que 2 hôtes plus un témoin et 3 clusters d’hôtes sont entièrement pris en charge et peuvent conserver une copie accessible des données pendant une panne, il n’est pas possible de reconstruire automatiquement ou de réparer automatiquement les composants dégradés. Il est également utile de prendre en compte les risques lors de la maintenance des hôtes, par exemple par le biais de correctifs ou de mises à jour. Si vous avez eu une panne avec un hôte déjà en mode de maintenance, il n’y aura pas suffisamment de copies des données pour maintenir la disponibilité.
En gardant cela à l’esprit, je recommande fortement de considérer un cluster de quatre hôtes lors du déploiement du vSAN.